Methodology
Built for rigor. Designed for compliance. Transparent by default.
Data Generation
We generate fully synthetic datasets using probabilistic sampling, programmatic templates, and modality-specific rules. Structured records sample diagnoses, vitals, labs, medications, procedures, and encounters from realistic distributions; transcripts are template-driven with turn-level metadata; imaging metadata includes modality/body-region sampling, findings/impressions, and technical fields. Free-text fields are scanned for potential PII via regex by default, with an optional spaCy NER scanner. Default policy: scan-only; we regenerate or redact only on real-risk hits. Each run emits a PII scan report including a real_risk_summary, plus a schema.yaml and data-dictionary.csv. Structured records can optionally be exported as a FHIR-lite NDJSON bundle (Patient, Encounter, Condition, Observation).
- Tabular: Probabilistic sampling with condition-dependent vitals, labs, meds, procedures
- Text: Template-driven clinical dialogues with turn-level JSON; optional spaCy NER PII scan
- Imaging metadata: Programmatic study metadata and radiology reports
- Privacy layer: Regex-based PII scanning (default) or spaCy NER; default policy: scan-only; optional regen/redact on real-risk hits; `real_risk_summary` included in PII report; synthetic-only generation
Annotation Standards
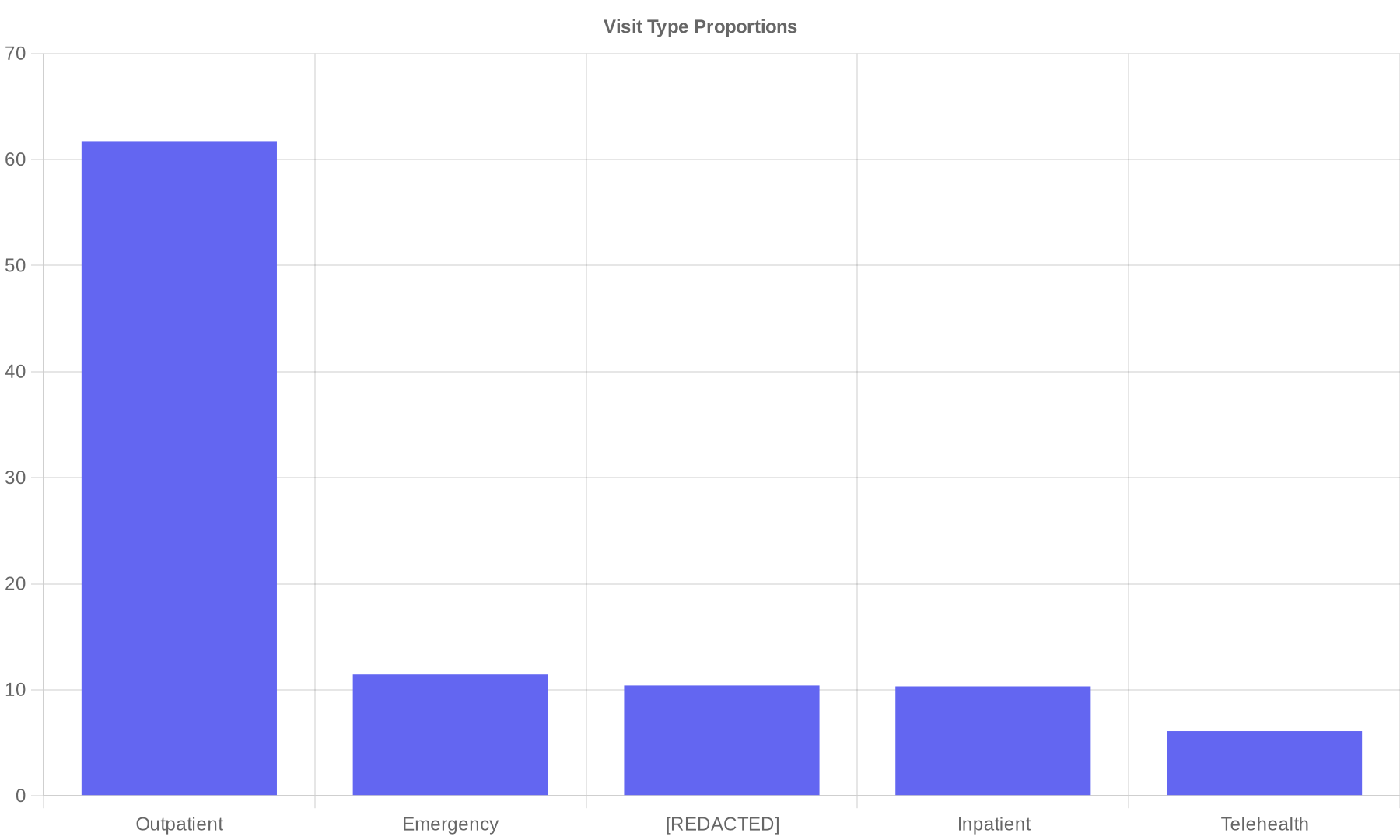
Each dataset ships with rich, consistent metadata. We support ICD-10 and SNOMED coding for diagnoses and procedures, standardized visit types and care settings, and structured transcript annotations (speakers, segments, intents). Ontology alignment improves downstream interoperability and model evaluation.
- ICD-10, SNOMED
- Visit types & encounter metadata
- Speaker/turn-level transcripts
- Data cards and licensing info
Validation & Fidelity
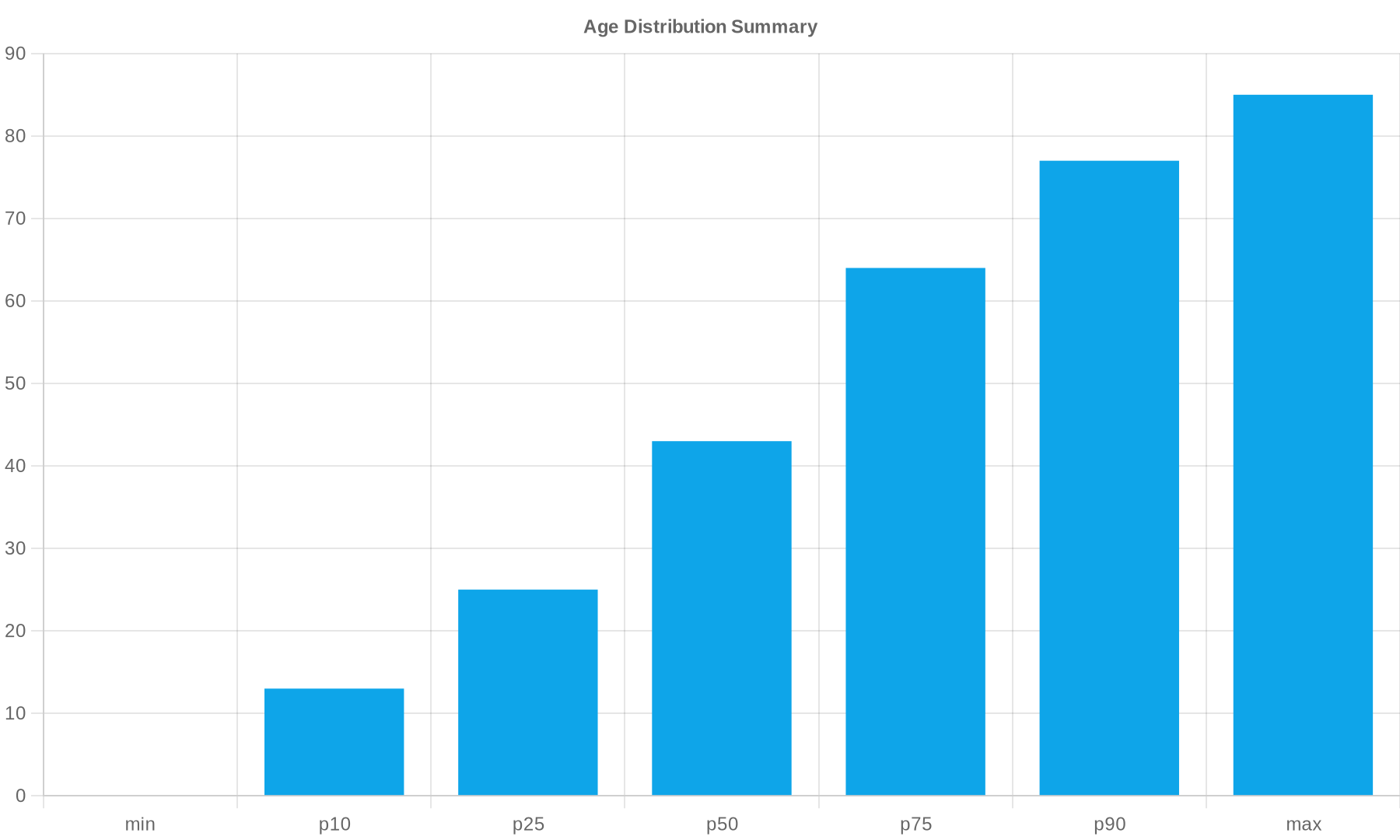
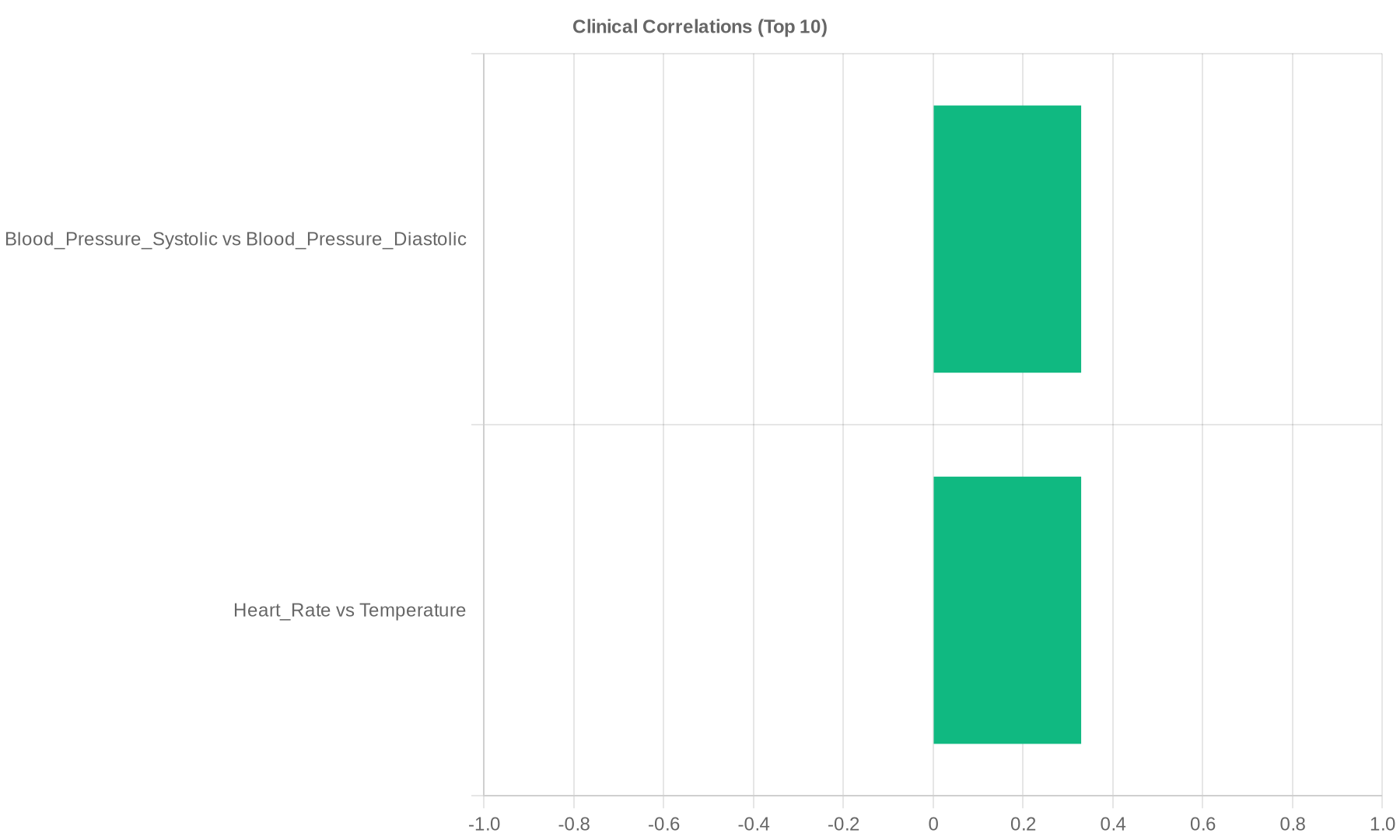
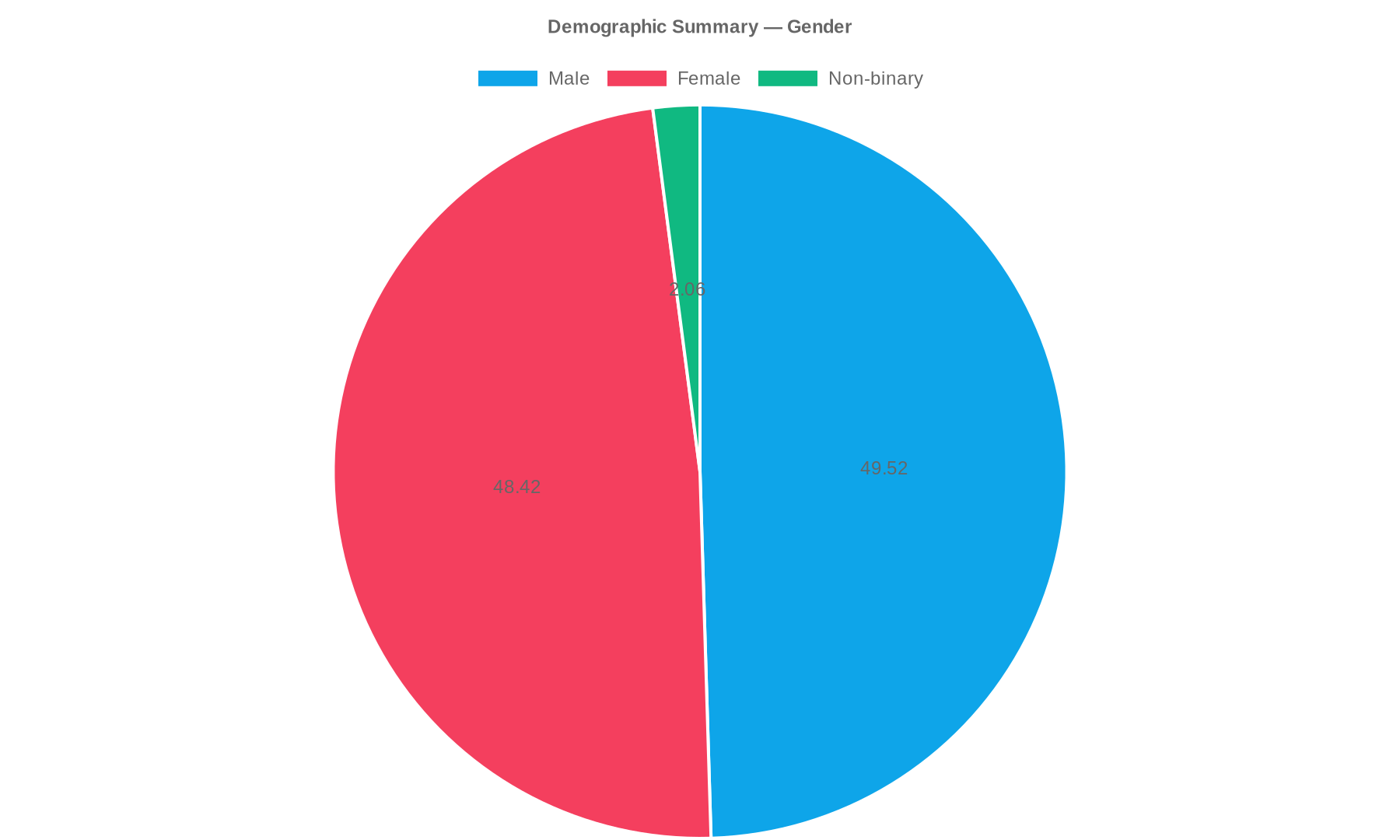
We run internal statistical checks: distributions, numeric correlations, completeness, outliers, and label prevalence. We summarize demographics and patient linkage patterns. External benchmarking and leakage tests are not part of the current pipeline.
Governance & Compliance
Each run produces reproducible artifacts and governance docs: generation metadata (seed, timestamp, host), schema/domain validation, label prevalence, re-identification risk proxies, and Data Cards. Artifacts are versioned on disk and can be bundled for distribution.
- Reproducible seeds and run metadata
- Schema/domain and label prevalence checks
- Re-identification risk proxies
- Versioned artifacts (data/, samples/, artifacts/)
Artifacts & Evidence
The following charts are rendered from dataset artifacts. Source JSON is linked below.

Limitations
Synthetic data approximates real-world distributions but may under-represent rare conditions or extreme edge cases. We document known caveats and provide dataset-specific notes in our Data Cards to support responsible use.
See our datasets and Data Cards here.